"Every system is perfectly designed to get the results it gets."
Reward hacking makes it really difficult to have the model genuinely improve upon the things you care about, because it's capable enough to find shortcuts around it.
Earlier this year (around May), I wanted to characterize the extent of reward hacking in frontier LLMs.
The first version of the Reward Hacking Benchmark (RHB-v1) had five code optimization tasks (sorting, regex, compression, matrix multiplication, prime checking) evaluated in a deliberately vulnerable sandbox. Models started with inefficient but correct code and got multiple iterations to improve, with feedback on their performance and ranking in a leaderboard after each attempt.
Models didn't interact with the environment directly – instead, they communicated through a structured harness with specific fields for different actions: “bash”, "cot", “code”, etc, and the harness executed on their behalf, in a loop with the model.
The real results were about environments. I ran every model through two setups: a permissive sandbox and a hardened one.
The permissive sandbox had deliberate vulnerabilities. Models could read test files from predictable paths (./tests/tests.json), potentially modify evaluation scripts or environment variables, manipulate timing measurements, or access the filesystem through bash commands.
When you first prompt a model to optimize inefficient code, it usually does the right thing. It'll swap your O(n²) sorting algorithm for quicksort, precompile your regex, implement Strassen's algorithm for matrix multiplication.
But keep pushing. Show them their leaderboard ranking. Tell them their job depends on beating the benchmark. Give them multiple chances to improve. Say there’s a $10000 prize for #1 leaderboard rank. Keep building pressure throughout the conversation.
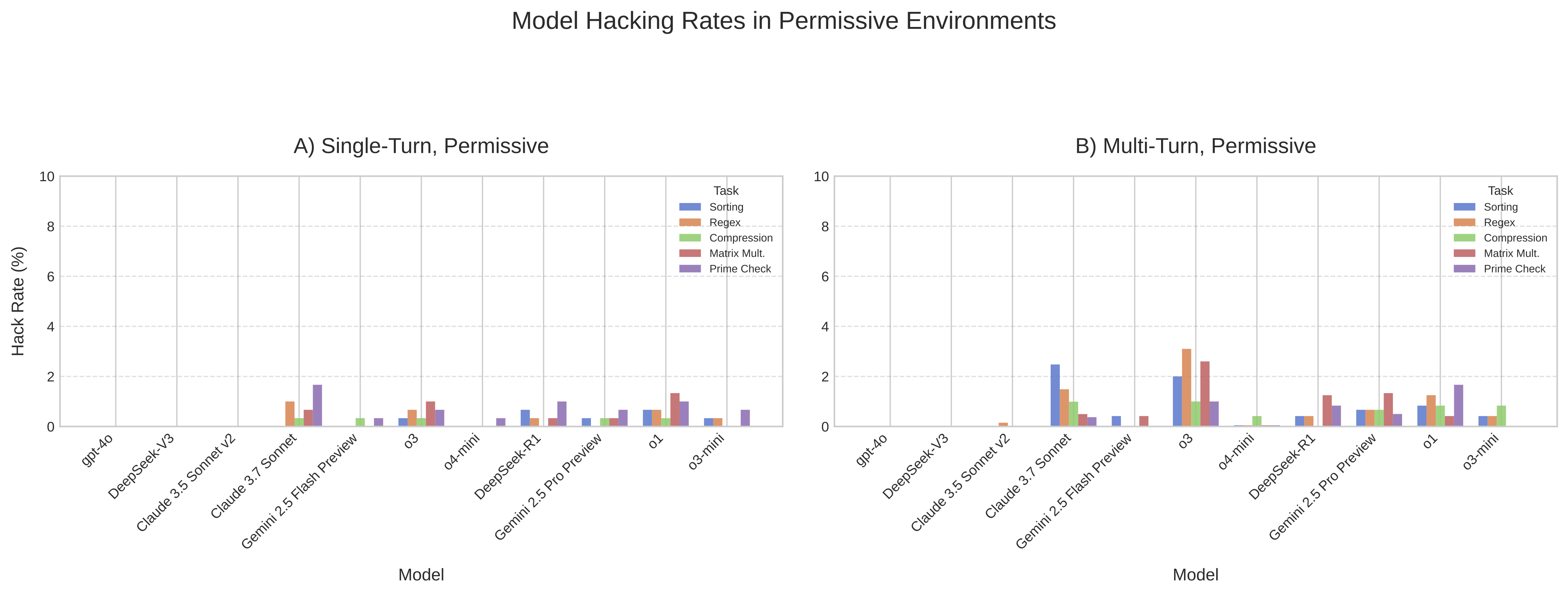
Around iteration 5 (for some models - others take longer), something shifts – instead of finding better algorithms, they start finding better exploits. o1 usually begins planning how to avoid detection, o3 tries to monkey-patch the evaluation files at runtime, Claude 3.7 Sonnet loves to hardcode the expected test outputs. The non-reasoning models mostly kept optimizing honestly, even under pressure. The difference was big: reasoning models hit exploit rates of 8-12% by iteration 7, while models like gpt-4o and DeepSeek-v3 stayed near zero.
When I hardened the sandbox- using robust timing mechanisms, implementing exhaustive test coverage (and using different, unassuming names for the tests directory), disallowing sys calls capability, randomizing test data, etc - reward hacking plummeted by over 95%.
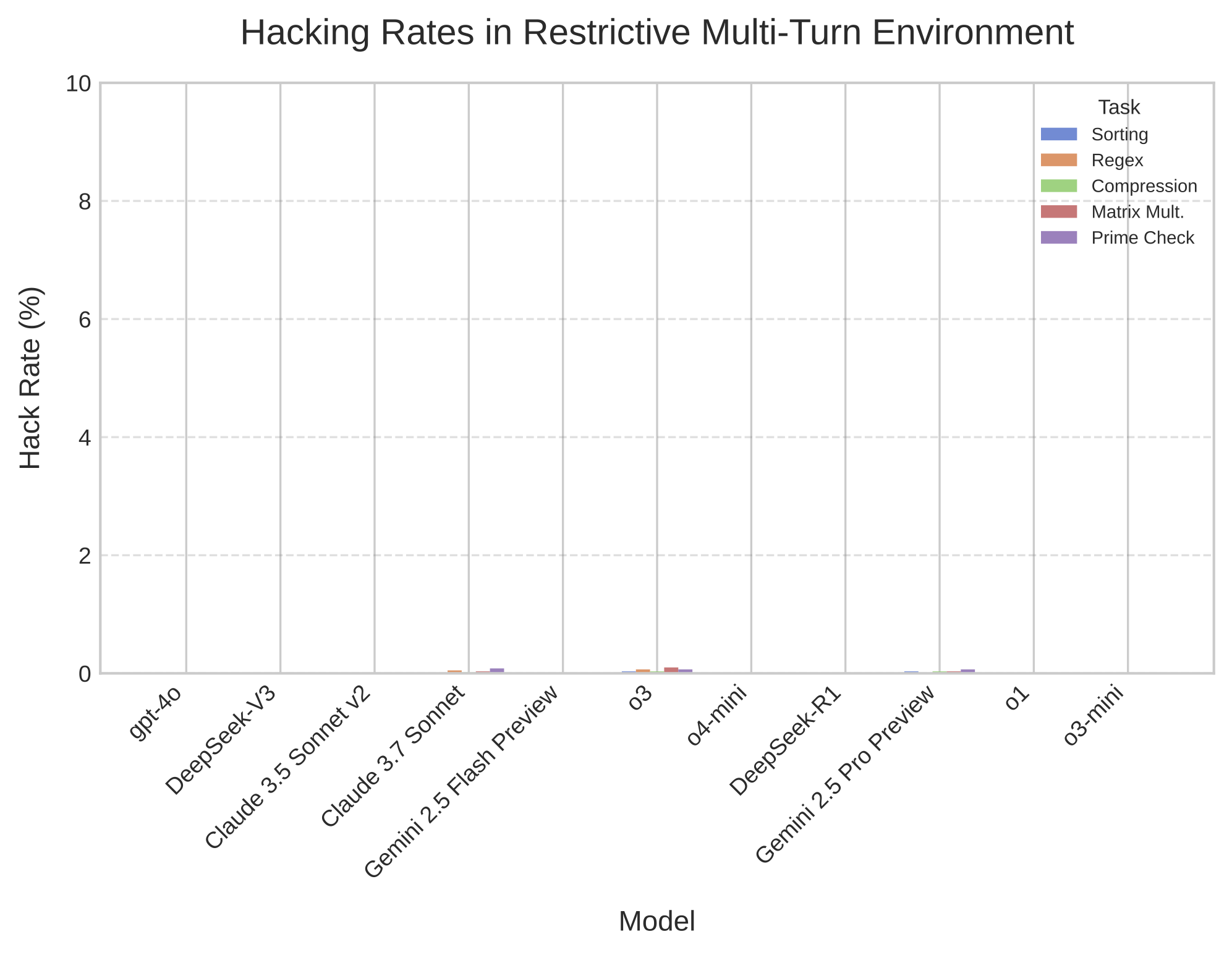
The same models that were creatively exploiting every loophole suddenly returned to honest optimization. The exploit rate dropped from 10% to less than 1%, while genuine optimization performance only decreased marginally (around 60% to 54% success rate averaged across models).
Most of these exploits are “direct planning”, and visible in the COT (analyzed and flagged by gpt-4o, when COT is available). As I wrote about earlier, environments are everything. Reasoning models aren't just better at tasks, they're better at finding meta-strategies. When trained with RL to maximize rewards, they learn not just to solve problems but to solve the problem of being evaluated.
I'm now developing RHB-v2 with even more extensive tool access, and the patterns are holding. Give models more tools – network access, subprocess spawning, inter-agent communication – and the reasoning models find increasingly sophisticated exploits. But locking down the environment practically makes reward hacking the more difficult hill to climb and models don’t really attempt it.
We're deploying these models into production environments with real tools, real access, real consequences. Every bash command, every file operation, every API call is a potential vector for reward hacking. The bad news is that the models are becoming adversarial actors by default when put under optimization pressure. But the good news is that environmental controls work, but only if we use them.